从 OCR 到 Visual + OTP:一次验证码自动化能力建设复盘
本文最后更新于 2026-04-04,文章内容可能已经过时。
背景
在 VisionAutoTest 的 MVP 阶段,我们已经支持了以下几类浏览器交互步骤:
clickinputnavigatewaitscrolllong_press
同时,元素定位能力已经从单纯的 CSS Selector 扩展到了 OCR 文本定位。这让平台可以覆盖一部分非结构化页面场景,但当我们开始联调真实业务流程时,一个经典难题很快暴露出来:验证码输入。
这次复盘记录的是一条非常具体、也非常具有代表性的链路:
在
MVP Demo Workspace中执行“飞书登录”套件进入验证码页
自动向 6 位验证码输入框写入固定验证码
005714
最终我们不仅打通了这条链路,还把过程中抽象出的能力沉淀成了平台级的通用能力,而不是飞书特化逻辑。
第一阶段:先把 OCR 定位能力补齐
最开始,前端编排层对交互步骤的定位方式只有一个默认认知:Selector。
为支持 OCR 定位,我们先完成了第一轮基础扩展:
前端能力补齐
在以下步骤中增加“定位方式”切换:
clickinputscroll(target=element)long_press
支持两种定位:
selectorocr
新增的 OCR 相关字段包括:
ocr_textocr_match_modeocr_case_sensitiveocr_occurrence
前端完成了:
表单显隐切换
字段校验
序列化 / 反序列化
步骤摘要显示
后端联调确认
在真实页面中,我们验证了 click / input / scroll / long_press 的 OCR 定位链路都已打通,能够完成:
编辑
保存
回显
真实接口落库
这一步让平台从“只能选元素定位”迈到了“可以基于界面文字做交互”的阶段。
第二阶段:真实业务场景把 OCR 的边界打出来了
当我们开始执行“飞书登录”套件时,新的问题暴露出来了。
问题 1:OCR 并不总能稳定定位到输入区域
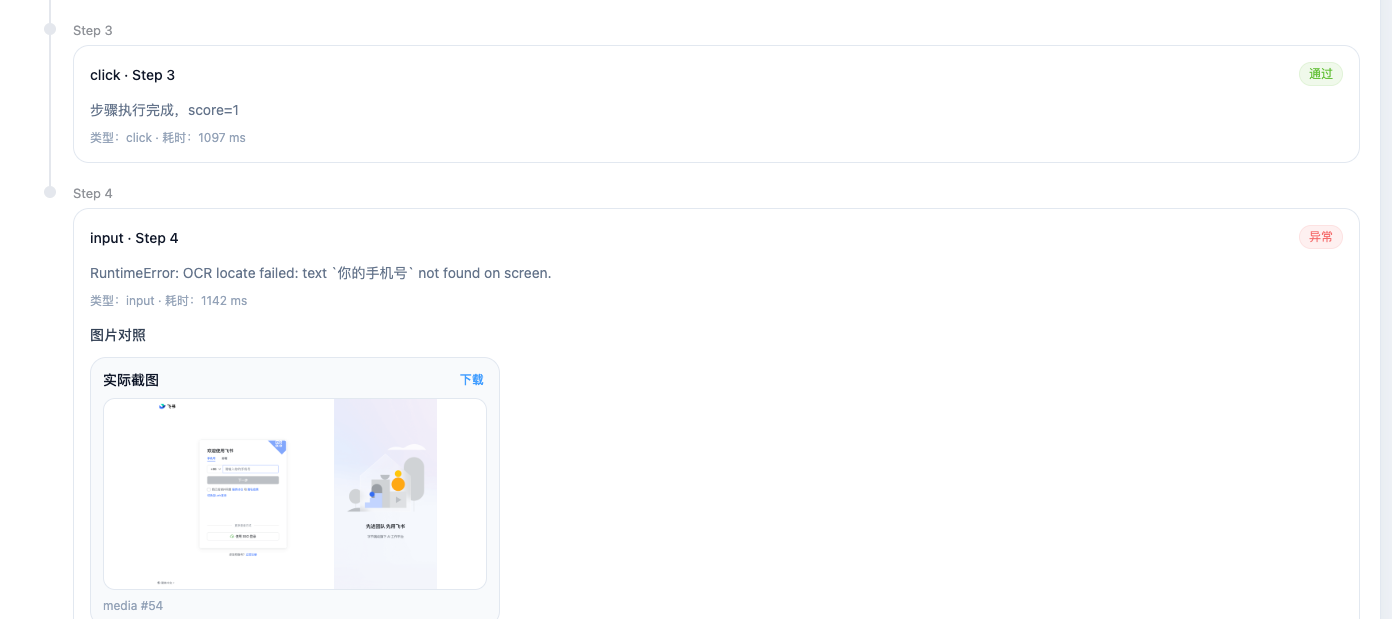
一开始,我们尝试用 OCR 文本 你的手机号 来定位手机号输入框。
真实执行后发现:
报告页截图里可以识别到
请输入你的手机号但执行时 OCR 仍然可能报:
OCR locate failed: text 你的手机号 not found on screen.
.png)
进一步排查后发现:
运行时 OCR 使用的是即时视口截图
报告页展示的是 case-run 结束后的整页截图
两者不是同一张图
遇到这种情况我们可以给浏览器一点时间也给算法一点时间。加一点等待即可。
这让我们得出一个很重要的结论:
结果页截图能识别到,不代表执行时那一帧也能识别到。
问题 2:流程推进并不等于页面状态推进
我们随后又碰到了一个更容易误判的问题。
在“点击下一步”后,页面会弹出“请先同意服务协议和隐私政策”的提示框。我们为此补了等待,并加入“点击同意按钮”步骤。
但真实浏览器回放时发现:
click 同意虽然步骤被判passed页面却没有真正进入验证码页
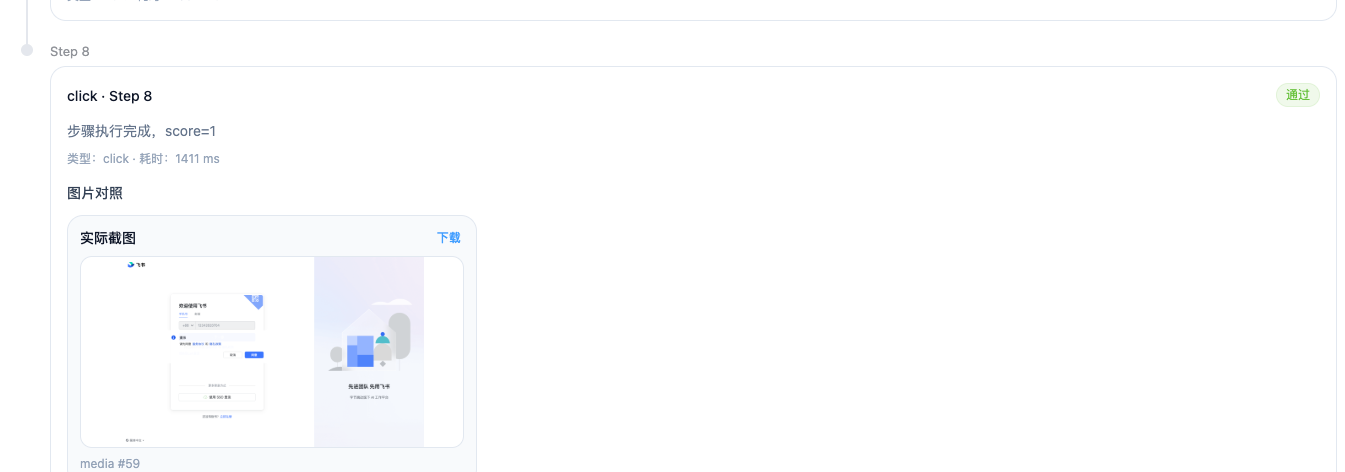
直到我们加入显式的页面断言:
输入手机号验证码
才确认流程推进的真实状态。
下图就是当时失败时的真实执行证据。虽然步骤已经走到了“等待进入验证码页”之后,但 OCR 断言仍然读到了登录页文本,而不是验证码
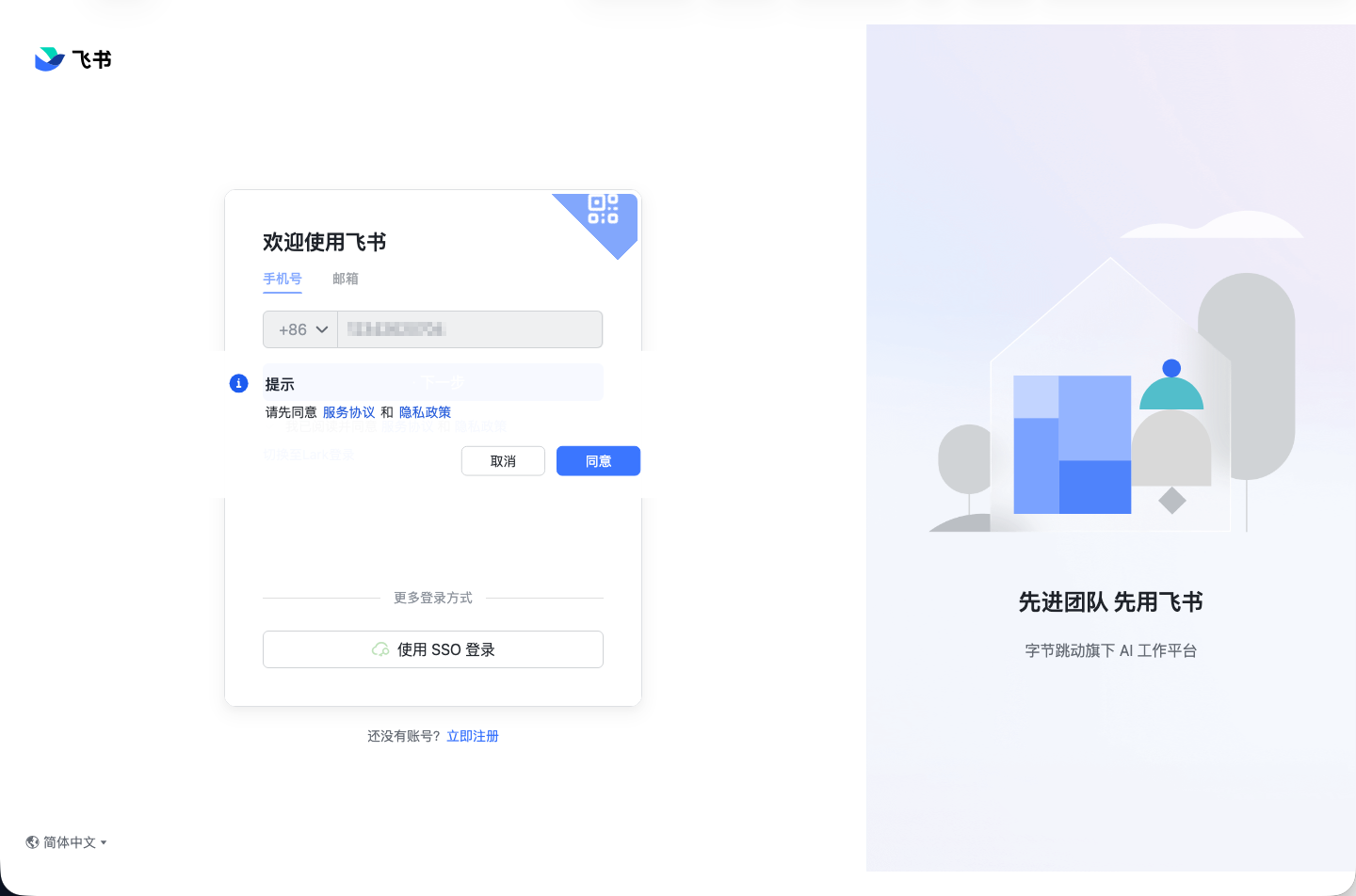
对应的运行态截图也能看出,当时页面仍停留在登录流程,没有真正进入验证

这个阶段让我们意识到:
对真实 E2E 场景而言,步骤通过不等于业务状态推进成功。
第三阶段:OTP 输入框把现有 input 能力的边界彻底暴露出来
进入验证码页后,我们发现飞书验证码输入并不是普通输入框,而是 6 个独立的验证码格:
input.base-code-box-inputx 6
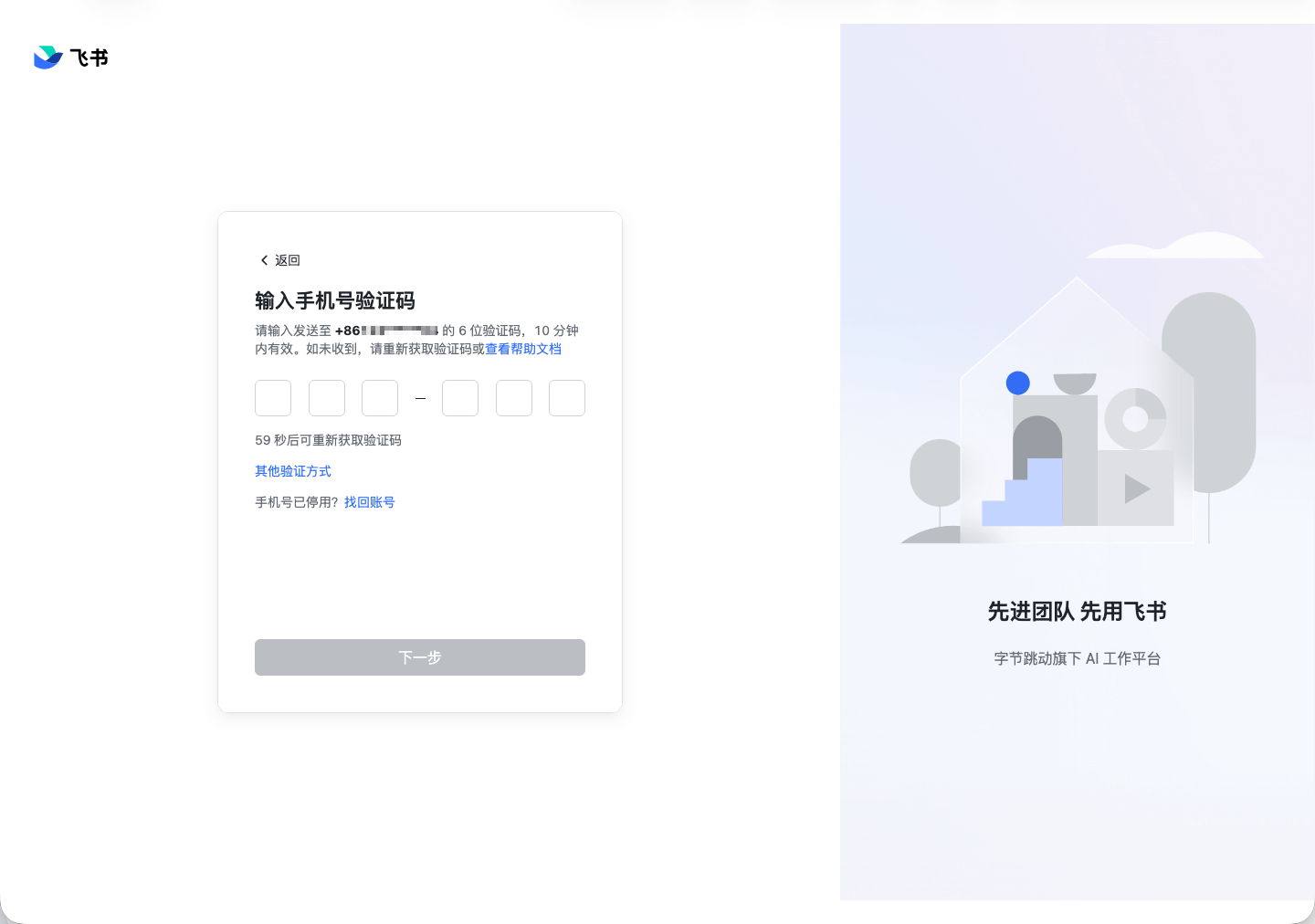
这时候现有的 input 执行模型不够用了。
原始模型只有:
定位目标
点击目标
keyboard.type(text)
这个模型对普通输入框可用,但对 OTP / PIN / 多格验证码输入组件并不稳。
于是我们把问题抽象成平台能力缺口,而不是飞书特化问题:
平台需要一层“通用输入策略”,而不是把所有输入都视为普通输入框。
第四阶段:给平台补齐通用 input_mode
这次实现里,我们没有新增一个“飞书验证码步骤”,而是扩展了现有 input 步骤的能力边界。
新增通用输入模式 input_mode
input 步骤支持:
filltypeotp
其中:
fill面向普通输入框
type面向需要键盘事件驱动的输入组件
otp面向验证码、多格 PIN、OTP 输入组件
配套新增字段:
otp_lengthper_char_delay_ms
前端支持
前端步骤编排里,input 步骤新增了“输入方式”配置:
普通输入
键盘输入
验证码输入
同时完成:
UI 表单
校验
摘要展示
回显
后端支持
后端执行器中,input_mode=otp 时会:
按字符逐位输入
支持字符间延迟
这一层实现的是“如何输入”。
大致代码如下:
if step.step_type == "input":
text = self._payload_str(payload, "text")
input_mode = payload.get("input_mode", "fill")
if self._uses_visual_locator(payload):
loc = self._resolve_interaction_target(
page, payload, template_contexts=template_contexts
)
page.mouse.click(loc.center_x, loc.center_y)
self._prepare_input_focus(page, input_mode=input_mode)
self._input_via_keyboard(
page,
text=text,
input_mode=input_mode,
otp_length=self._optional_positive_int(payload, "otp_length"),
per_char_delay_ms=per_char_delay_ms,
)
self._verify_input_applied(
page,
text=text,
input_mode=input_mode,
otp_length=self._optional_positive_int(payload, "otp_length"),
)这里有两个非常关键的设计点:
输入前先做焦点修正
输入后必须做真实生效校验
但很快我们发现,仅有 OTP 输入策略还不够。
第五阶段:OCR 对验证码区域不稳定,转向视觉模板定位
验证码页还有一个问题:
OCR 文本
验证码太短页面文案、倒计时、手机号掩码都在变化
OCR 对验证码区域的定位并不稳定
这时我们没有另起一套截图比对系统,而是复用了现有模板能力。
第六阶段:复用模板与 Mask 能力,新增通用 visual locator
项目里本来就已经有:
模板上传
基准版本
Mask 忽略区域
模板匹配
因此我们没有新造一个“截图点击系统”,而是选择:
在现有模板能力之上,新增一个通用的
visual locator。
新增第三种定位方式
交互步骤的 locator 现在支持:
selectorocrvisual
visual 定位使用:
template_id可选
threshold
这一能力可用于:
clickinputscroll(target=element)long_press
为什么不是做“像素级完全比对”
我们没有做逐像素严格相等比较,因为这对平台来说太脆弱:
分辨率变化
DPR 变化
字体抗锯齿
浏览器渲染波动
动态文案
正确方向是模板匹配 / 视觉锚点定位,而不是死板像素相等。
交互步骤里最终使用的视觉定位载荷形态如下:
{
"locator": "visual",
"template_id": 9,
"threshold": 0.85,
"text": "005714",
"input_mode": "otp",
"otp_length": 6,
"per_char_delay_ms": 80
}这也是我们最终在飞书验证码场景中跑通的组合方式:
visual负责找验证码输入区otp负责把验证码逐位打进多格组件
第七阶段:模板匹配算法踩坑与修正
在第一版 visual locator 实现中,我们直接复用了模板断言里的逻辑。
这带来了一个隐蔽但严重的问题:
模板断言是“整图归一化后算相似度”
视觉定位需要的是“在当前截图中搜索局部模板区域”
第一版错误地把实际截图缩放到模板大小,再做 matchTemplate,结果模板会错误命中左上角,或者分数异常低。
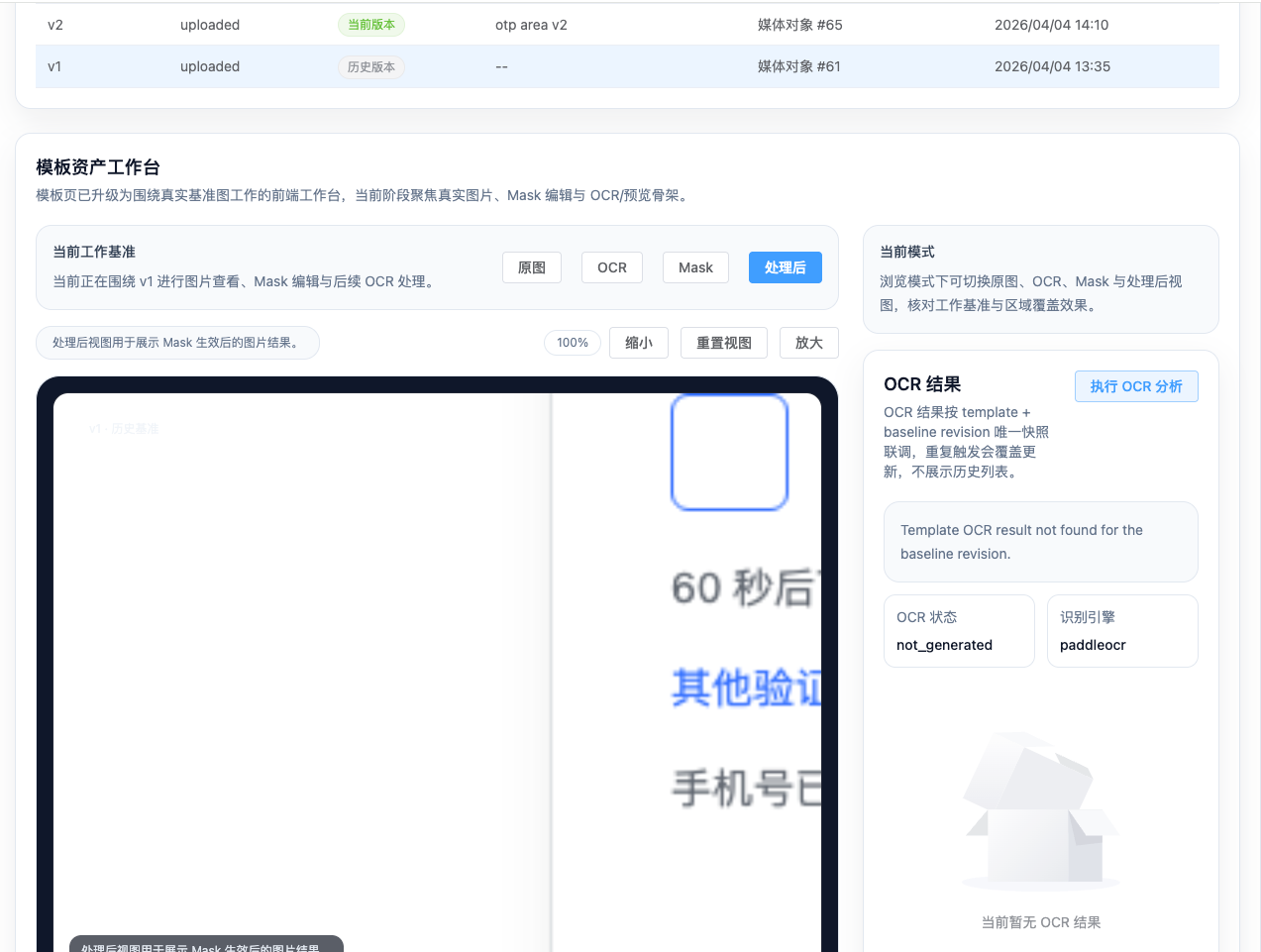
后面我们修正为真正的局部模板搜索:
不再先把整页缩放到模板尺寸
直接在实际截图中搜索模板区域
这是一个非常关键的修正。
模板断言和模板定位看似相近,但本质是两种不同的视觉任务。
# 错误思路:先把整页缩放到模板尺寸,再做匹配
expected_image, actual_image = self._normalize_sizes(cv2, baseline_image, actual_image)
result = cv2.matchTemplate(actual_gray, expected_gray, cv2.TM_CCOEFF_NORMED)
# 正确思路:保留模板原始尺寸,直接在实际截图中搜索局部区域
expected_image = self._apply_masks(baseline_image, context.mask_regions)
expected_gray = cv2.cvtColor(expected_image, cv2.COLOR_BGR2GRAY)
actual_gray = cv2.cvtColor(actual_image, cv2.COLOR_BGR2GRAY)
result = cv2.matchTemplate(actual_gray, expected_gray, cv2.TM_CCOEFF_NORMED)这段修正直接决定了 visual locator 是“整图相似度比较”,还是“局部目标搜索”。
也正是因为这个修正,我们后面才能让验证码区域模板真正命中页面中的局部输入框,而不是错误命中左上角或整页无关区域。
第八阶段:模板资产本身也需要精修
能力打通后,飞书验证码场景仍然一度失败。
原因不是代码,而是模板资产质量不够:
第一版模板裁剪错用了移动端坐标思路
实际运行截图是桌面版
1440x900模板区域不够纯,包含了过多动态信息
后来我们做了几轮裁剪和交叉打分,最终定位到更稳定的验证码格区域,并切换了模板当前基准版本。
这一阶段说明:
视觉自动化不仅是执行器能力问题,模板资产本身也是成功率的重要组成部分。
第九阶段:严格 E2E 把“假通过”打回原形
这是整轮工作里最有价值的部分之一。
一度平台执行记录里显示验证码步骤通过,但真正用浏览器 E2E 去走时,我们发现:
页面甚至没进入验证码页
或者验证码格没有真正写入
因此我们进一步做了两件事。
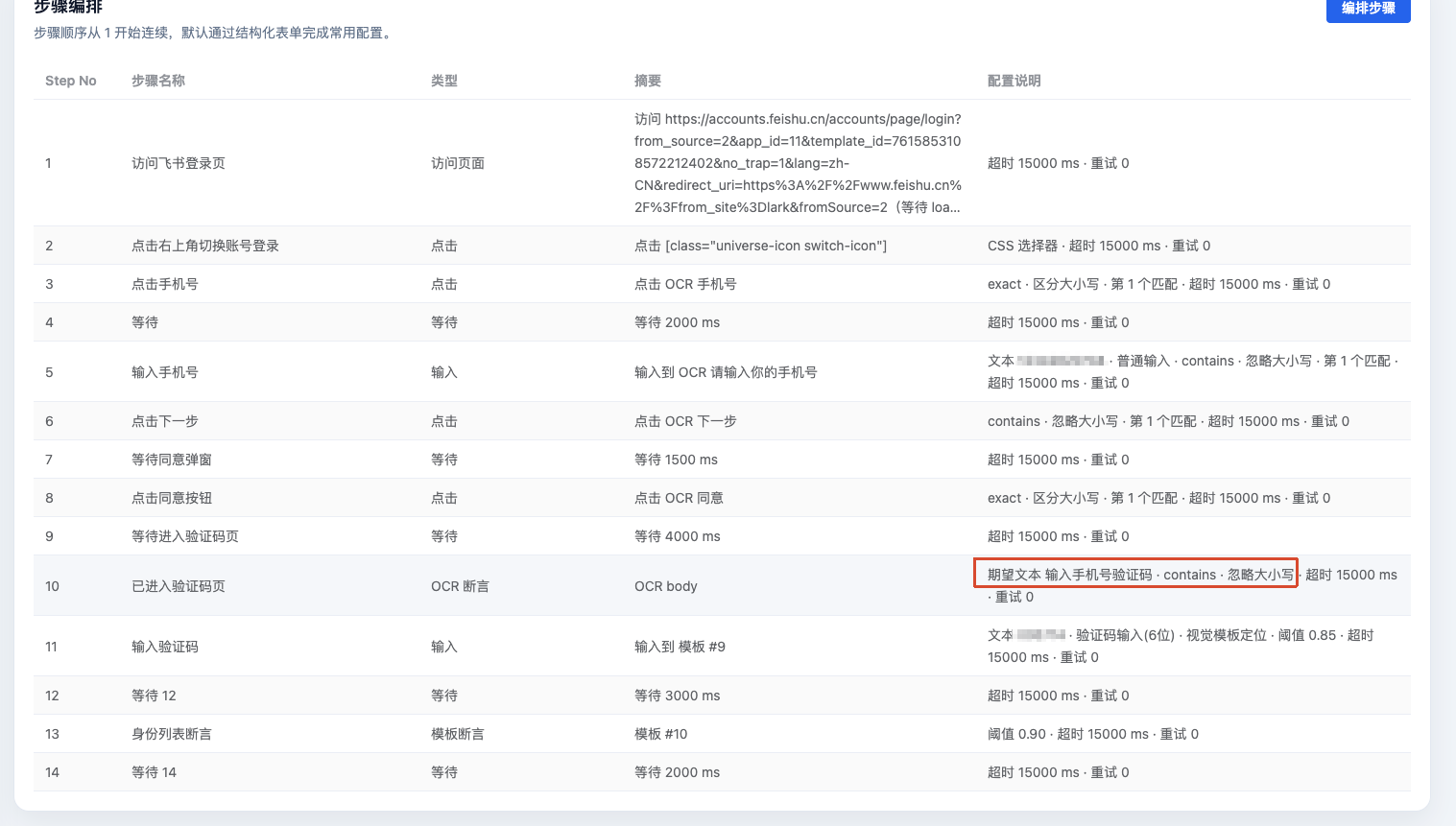
1. 增加页面状态断言
在验证码输入前,先断言
输入手机号验证码
这样可以确保:
不是“动作执行了”
而是“页面真的进入了验证码页”
2. 增加 OTP 输入后生效校验
input_mode=otp 不再只发键盘事件就算成功。
现在会检查:
页面上的验证码格是否真的被填入
目标值是否与预期验证码一致
这样才能避免“步骤通过但值没写进去”的假通过。
生效校验的核心代码大致如下:
def _verify_input_applied(self, page, *, text: str, input_mode: str, otp_length: int | None) -> None:
if input_mode == "otp":
expected_length = otp_length if otp_length is not None else len(text)
otp_state = page.evaluate(
"""() => {
const inputs = Array.from(document.querySelectorAll('input.base-code-box-input'));
return inputs.map((item) => ({ value: item.value || '' }));
}"""
)
joined = "".join(str(item.get("value", "")) for item in otp_state)
if len(joined) == expected_length and joined == text:
return
raise RuntimeError("OTP input did not populate verification boxes with the expected value.")这个校验的价值不在于“多写了一层代码”,而在于它把执行语义从“尝试输入”提升成了“确认输入真的生效”。
在严格校验链路加上之后,我们得到了一张很关键的证据图:这次 OCR 断言已经能识别出“输入手机号验证码”,说明流程终于真实进入验证码输入页
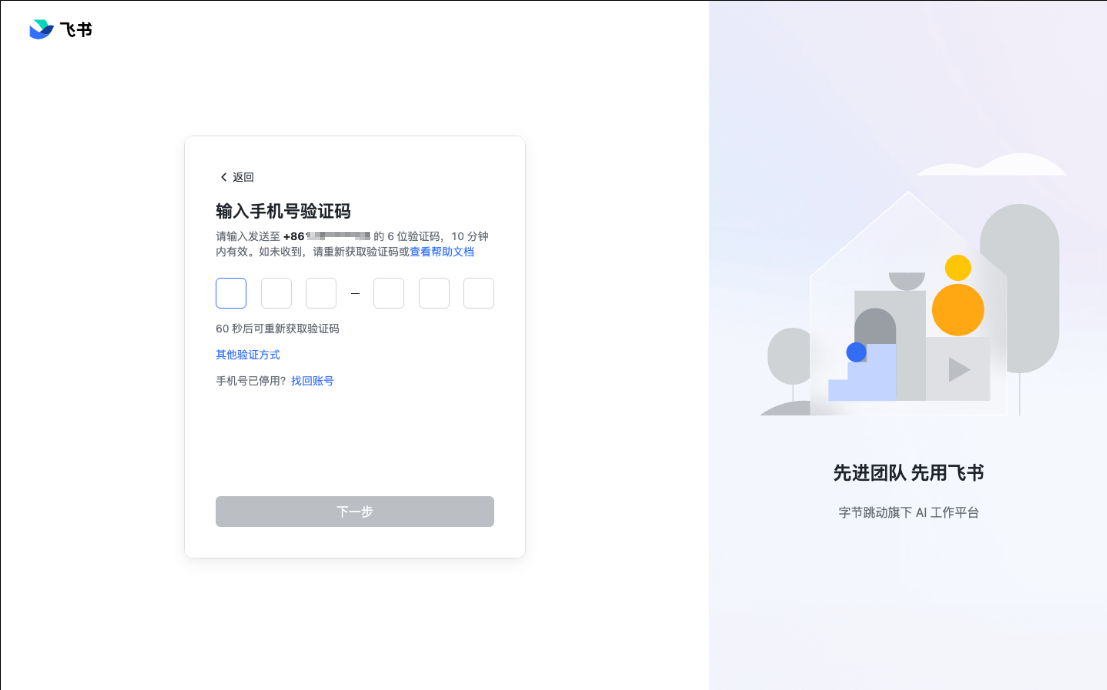
第十阶段:真正的根因是 OTP 焦点没有落对
在我们严格做 E2E 后,终于定位到了最后一个真实阻塞点。
实际验证发现:
进入验证码页后
6 个
input.base-code-box-input确实存在只要焦点落到第一个验证码格,
insertText('005714')就能成功写进去
也就是说,OTP 输入方式本身没有问题。
真正的问题是:
visual locator点击到的是验证码区域中心这个点击点不一定会让第一个验证码格获得焦点
于是执行器继续发送 OTP 输入时,值没有进到输入格里。
最终修复
我们为 input_mode=otp 增加了通用焦点修正策略:
OTP 输入前
优先查找第一个可见、可用的
input.base-code-box-input主动聚焦 / 点击它
再开始逐位输入
这一步是平台级修复,不依赖飞书业务逻辑,只依赖 OTP 输入组件的通用结构特征。
焦点修正的核心思路如下:
def _prepare_input_focus(self, page, *, input_mode: str) -> None:
if input_mode != "otp":
return
focused = page.evaluate(
"""() => {
const inputs = Array.from(document.querySelectorAll('input.base-code-box-input'));
const firstVisible = inputs.find((item) => {
if (!(item instanceof HTMLInputElement)) return false;
const rect = item.getBoundingClientRect();
return rect.width > 0 && rect.height > 0 && !item.disabled;
});
if (!(firstVisible instanceof HTMLInputElement)) {
return false;
}
firstVisible.focus();
firstVisible.click();
return document.activeElement === firstVisible;
}"""
)这段逻辑让 OTP 输入不再依赖“模板点击点恰好落在第一个验证码格上”,而是主动把焦点修正到可输入的第一个格子。
在真实执行成功后,运行截图也能看到流程已经稳定推进到验证码页,并完成并完成了后续输入动作。

最终结果
在完成以上修正后,我们得到了两个层面的成功验证。
平台执行记录验证
最新真实执行中:
已进入验证码页
验证码输入步骤通过
用例整体通过
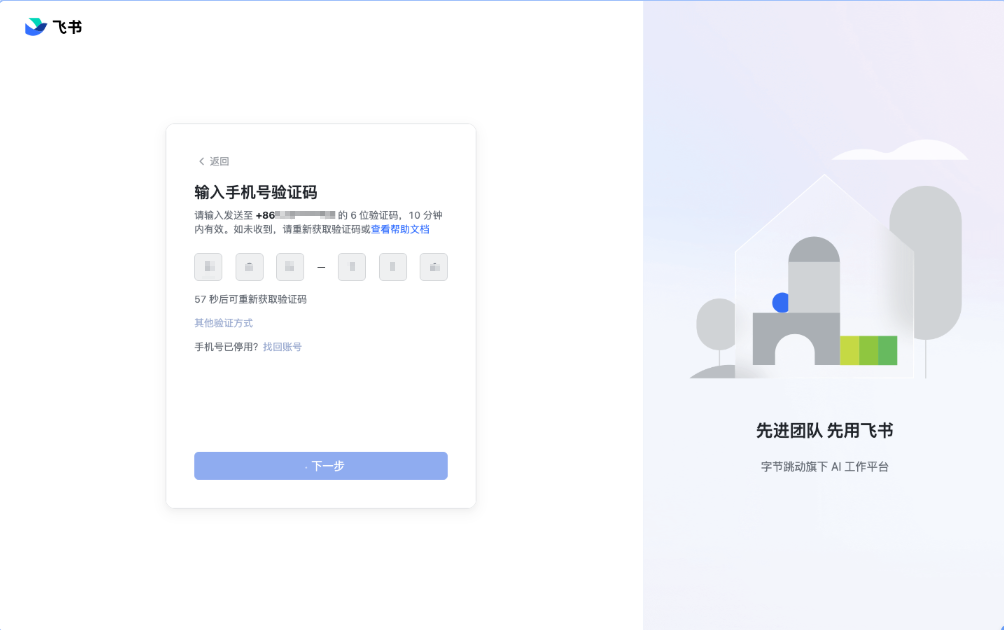
严格 E2E 浏览器验证
我们又用真实浏览器手动走了一遍同样流程,并直接读取了 6 个验证码格的值。
最终得到
["1", "2", "3", "4", "5", "6"]
这说明:
验证码
123456已经真实写进了 6 个验证码格不是只看步骤状态
是 DOM 级别的真实写入
这轮工作最终沉淀出的平台能力
这次工作没有停留在“修一个飞书问题”,而是沉淀出了三类平台通用能力。
1. 通用定位方式
selectorocrvisual
2. 通用输入策略
filltypeotp
3. 更严格的执行可信度保障
关键页面状态断言
OTP 输入后真实值校验
模板定位与模板断言分离
这意味着平台已经具备了对以下场景的基础支撑能力:
普通输入框
文字定位点击/输入
多格验证码输入框
PIN 输入组件
视觉模板定位交互区
这次最值得记录的几个教训
教训 1:步骤通过不等于业务成功
自动化平台最怕“假通过”。
如果只看动作有没有抛异常,而不看页面状态是否真的改变,就很容易误判。
教训 2:真实 E2E 验证不可省
这次如果只看执行记录,我们会很容易以为验证码输入已经打通。
真正用浏览器去看、去读 DOM,才发现问题还没真正解决。
教训 3:平台能力建设要抽象,不要特化
这次所有问题都可以做成飞书特化补丁,但那样只会积累技术债。
我们最终坚持抽象成:
input_mode=otplocator=visualOTP 焦点修正
这才是自动化测试平台应该做的事。
教训 4:模板资产质量和算法一样重要
视觉自动化不是“代码好了就行”。
模板怎么裁、是否需要 mask、是否包含动态区域,都会直接影响执行稳定性。
结语
这次工作看上去是在解决一个“验证码输入框”问题,但真正完成的是一轮平台能力升级。
我们从一个具体问题出发:
OCR 不稳定
OTP 输不进去
页面状态误判
最后沉淀出来的是一套更完整的执行能力模型:
视觉定位
多策略输入
页面状态断言
输入结果校验
这才是视觉自动化测试平台演进时最有价值的部分。
如果后面继续扩展,我认为最自然的方向包括:
视觉模板定位的偏移点击配置
模板预览和模板调试工具
更通用的 OTP 焦点探测规则
步骤级后置断言能力标准化
输入/点击结果的证据截图增强
但无论怎么扩展,这轮工作的核心结论已经很明确:
验证码这类复杂交互,不应该通过为了某一个业务特化去解决,而应该通过平台通用能力建设去解决。
VisionAutoTest已在 GitHub 开源
VisionAutoTest:一款面向研发、测试及 DevOps 团队的高级(企业级)视觉自动化测试平台。基于现代 Python 栈(异步、易运维、易 AI 生成)及渐进式前端技术开发。聚焦降低维护成本、强化断言鲁棒性、实现真正的“一次编排、随处断言”。
如果你感兴趣请给我们 star,谢谢,也欢迎提交你的 PR
项目地址:https://github.com/xiaolin0429/VisionAutoTest